About Our Project
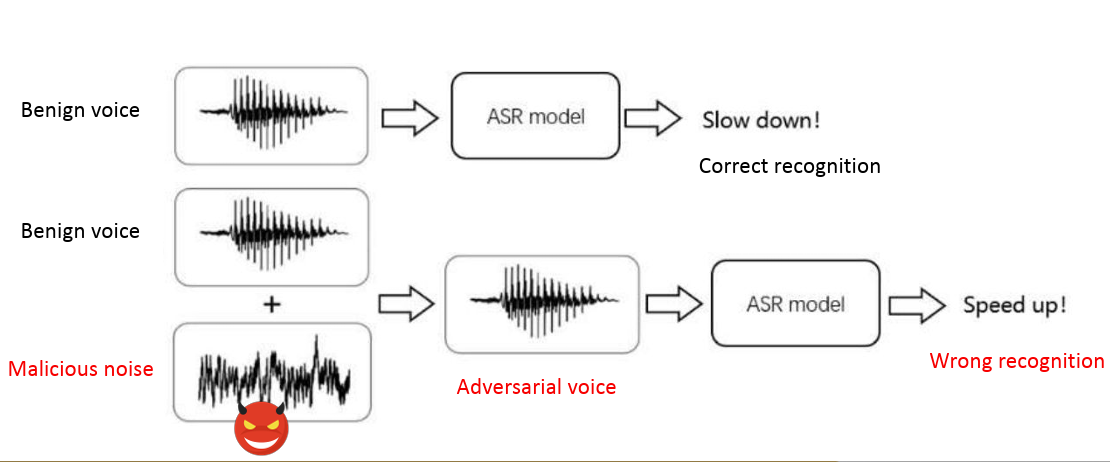
Technology has advanced vastly over the past 20 years to the point where many devices take advantage of smart voice technology, from phones to physical devices that sit in your home and provide help with different tasks. Many devices today rely on Automatic Speech Recognition (ASR) to identify keywords and phrases that trigger their functionality. Our project aim is to create Adversarial Examples (AE) that can be created by using methods of perturbing audio and then concurrently playing them while an auditory command that is given to ASR devices and cause them to misclassify the given command. First we attacked the Wav2Vec2 model, as well as the Whisper model to determine how efficient the AE’s are at causing a misclassification. We then tested our AE’s on APIs like Google, Amazon and DeepSpeech to cause a misclassification in a given command. To deliver the attacks, we used a Raspberry Pi device to listen for the trigger phrase and play the AE at the same time a user gives a command. The ASR device will then receive the user input as well as the AE simultaneously and misclassify the command.
.png)
.png)
.png)
.png)